2021/09/26 13:46 IT��ҵ��
�����εμ�����Ϊ������������ͷ����ҵ������ȫ����Ժ�����StarRocks�����г�����ѡ����һ����������ϵ���裬������һ������Ҫʵʱ������ѯ����ϯ��ѯ�Ķ�ά���ݷ���������ClickHouseǨ�Ƶ���StarRocks�У�StarRocks���ȶ��ԡ�ʵʱ�Է���Ҳ�����������õ����飬��������StarRocksʵ�ֵ�©������Ϊ������StarRocks�ڳ�����ѡ��Ӫ���ݷ���Ӧ���е�ʵ����
�������ߣ����� �εγ�����ѡ���ݼܹ����������ݼܹ���������ʦ�����������ѡ�����ݻ������������Ӧ�õĿ����뽨��
�����������
������ǰ���������Ż��ϵ�©�����������ɢ��ÿ������ͨ��ֻ��֧��һ��������©���������������û�ͳһ���������Աȵȣ�������֧����ѡ©�����衢��������������Ĺ��ܡ���ˣ�������Ҫһ���ܸ��Ǹ�ȫ���������ݣ�֧�����ɸѡά�ȡ����ѡ��©�����ṩ���ַ����ӽǵ�©���������ߣ�����λ��ʧ��Ⱥ��ת����Ⱥ���Ӷ���С���ⷶΧ�����ҵ���Ӫ���ԡ���Ʒ����Ż��㣬ʵ�־�ϸ����Ӫ��
��������ѡ��
�������̳�����������־����Ϊ��־һ���ȴ�ͳ�����µ���������ܶ࣬����������ı�������©�����������Ǵ�������������ս��
����·����������������ǧ�����ݣ�֧�����ѡ��ά�ȣ���ο��ٵض��ڼ����������ж�ά����
����·�����ݷ���ʱЧ��Ҫ��ߣ���ο��ٵػ����ڼ���������ȷȥ�أ���ȡ�����������û�����
����StarRocks��ClickHouse�ڳ����ڲ����й㷺��Ӧ�ã�����Ҳ�����˷ḻ�ľ��飬��StarRocks�������ԺͿ�ά�����϶���ClickHouse��ʤһ��������ű�����������ʹ�ù����ж����߹��ܵ�һ���Աȣ�

�����������ϵضԱȺ�ѹ�⣬�������վ���ʹ��StarRocks���洢��Ҫ����©�����������ݣ���ΪStarRocks��SQL��ء���ά�������ClickHouse���������ԣ��������ǿ���Ϊ�����㲻ͬ�IJ�ѯ����������©��������ϸ���������ָ������ﻯ��ͼ����߶�ά���ݷ������ٶȡ�
����ϵͳ�ܹ�
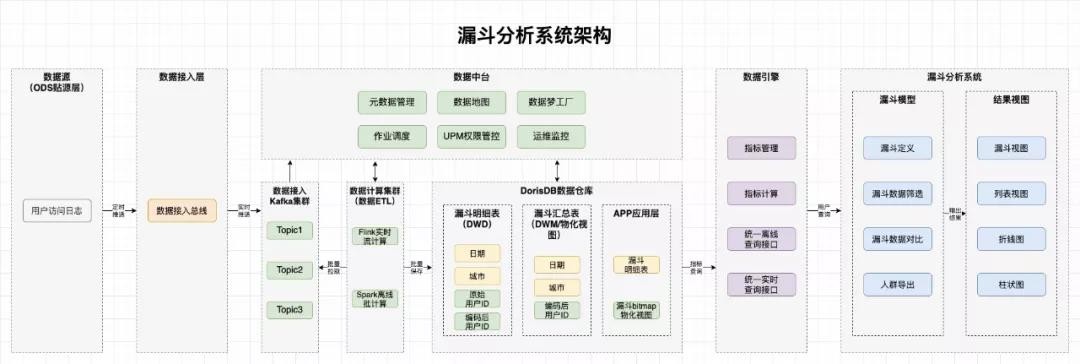
����ϵͳ����ְ��˵�����£�
����1������Դ����Ҫ��web�ˡ��ͻ��˵������־����Щ�����־ԴԴ���ϵ��ϴ������ǵ����ݽ����
����2�����ݽ���㣺
����(1)���ݽ������ߣ��ṩ��������Դ�Ľ���ӿڣ����ղ�У�����ݣ���Ӧ�ò����θ��ӵ����ݸ�ʽ���������־����У��ͼ���ϴ��ת������־�������͵�Kafka��Ⱥ
����(2)Kafka��Ⱥ�����ݽ������������ݼ��㼯Ⱥ���м�㡣���ݽ������ߵĶ�Ӧ�ӿڽ����ݽ��ղ�У����ɺ�����ͳһ����Kafka��Ⱥ��Kafka��Ⱥ���������ݽ������ߺ����ݼ��㼯Ⱥ������Kafka������������ʵ���������ƣ��ͷŸ߷�ʱ��־��������������μ��㼯Ⱥ���洢ϵͳ��ɵ�ѹ��
����3�����ݼ�����洢�㣺
����(1)���ݼ��㼯Ⱥ�����ݴ���Kafka��Ⱥ���ݲ�ͬ��ҵ������ʹ��Flink����Spark�����ݽ���ʵʱ������ETL�����������浽StarRocks���ݲֿ�
����(2)StarRocks���ݲֿ⣺Spark+Flinkͨ����ʽ���ݴ�����ʽ�����ݴ���StarRocks�����ǿ��Ը��ݲ�ͬ��ҵ����StarRocks�ﴴ����ϸ�����ۺϱ����±��Լ��ﻯ��ͼ������ҵ����������ʹ��Ҫ��
����4�����ݷ���㣺�ڲ�ͳһָ�궨��ģ�͡�ָ���������Ϊ����Ӧ�÷��ṩͳһ�����߲�ѯ�ӿں�ʵʱ��ѯ�ӿ�
����5��©������ϵͳ��֧�������ͱ༭©����֧��©�����ݲ鿴��©����ϸ���ݵ���
����6��������̨��Χ�ƴ���������������ʹ�ó������ṩԪ���ݹ��������ݵ�ͼ����ҵ���ȵ�ͨ�û���������������������ʹ��Ч��
������ϸ���
����Ŀǰ������StarRocks��bitmap����ֻ�ܽ�������ֵ��Ϊ���룬��������ԭʼ����user_id������ĸ���ֻ�ϵ��������ֱ��ת�������ͣ����Ϊ��֧��bitmap���㣬��Ҫ����ǰ��user_idת����ȫ��Ψһ������ID�����ǻ���Spark+Hive�ķ�ʽ������ԭʼ�û�ID������������û�IDһһӳ���ȫ���ֵ䣬ȫ���ֵ䱾����һ��Hive����Hive���������У�һ����ԭʼֵ��һ���DZ����Intֵ��������ȫ���ֵ�Ĺ������̣�
����1����ԭʼ�����ֵ���ȥ��������ʱ����
������ʱ�����壺
����create table 'temp_table'{
����'user_id' string COMMENT 'ԭʼ��ȥ�غ���û�ID'
����}
�����ֵ���ȥ��������ʱ����
����insert overwrite table temp_table select user_id from fact_log_user_hive_table group by user_id
����2����ʱ����ȫ���ֵ����left join�����յĴʵ���Ϊ��value������value���б��벢����ȫ���ֵ䣺
����ȫ���ֵ�����壺
����create table 'global_dict_by_userid_hive_table'{
����'user_id' string COMMENT 'ԭʼ�û�ID',
����'new_user_id' int COMMENT '��ԭʼ�û�ID�����������û�ID'
����}
��������ʱ����ȫ���ֵ�����й�����δƥ���еļ�Ϊ�����û�����Ҫ�����µ�ȫ��ID�����ӵ�ȫ���ֵ���С�ȫ��ID�����ɷ�ʽ��������ʷ���е�ǰ�������û�ID���������û����кţ�
����--4 ����Hive�ֵ��
����insert overwrite global_dict_by_userid_hive_table
����select user_id, new_user_id from global_dict_by_userid_hive_table
����--3 ����ʷ���ֶ�������
����union all select t1.user_id,
����--2 ����ȫ��ID����ȫ���ֵ���е�ǰ������û�ID���������û����к�
����(row_number() over(order by t1.user_id) + t2.max_id) as new_user_id
����--1 ���������ȥ��ֵ����
����from
����(
����select user_id from temp_table
����where user_id is not null
����) t1
����left join
����(
����select user_id, new_user_id, (max(new_user_id) over()) as max_id from
����global_dict_by_userid_hive_table
����) t2
����on
����t1.user_id = t2.user_id
����where t2.newuser_id is null
����3��ԭʼ�����º��ȫ���ֵ������left join���������û���ID�ͱ����������û�ID���뵽ԭʼ���У�
����insert overwrite fact_log_user_hive_table
����select
����a.user_id,
����b.new_user_id
����from
����fact_log_user_hive_table a left join global_dict_by_userid_hive_table b
����on a.user_id=b.user_id
����4������Spark����ͬ���������Hiveԭʼ����StarRocks��ϸ��������ͬ����StarRocks��fact_log_user_doris_table����(Hive��fact_log_user_hive_table��ñ��Ľṹһ��)��
����CREATE TABLE `fact_log_user_doris_table` (
����`new_user_id` bigint(20) NULL COMMENT "�����û�id",
����`user_id` varchar(65533) NULL COMMENT "�û�id",
����`event_source` varchar(65533) NULL COMMENT "��(1���̳�С���� 2���ų�С���� 3������APP 4������)",
����`is_new` varchar(65533) NULL COMMENT "�Ƿ����û�",
����`identity` varchar(65533) NULL COMMENT "�û�����(�ų�������ͨ�û�)",
����`biz_channel_name` varchar(65533) NULL COMMENT "�����״����ҳ��������",
����`pro_id` varchar(65533) NULL COMMENT "ʡID",
����`pro_name` varchar(65533) NULL COMMENT "ʡ����",
����`city_id` varchar(65533) NULL COMMENT "����ID",
����`city_name` varchar(65533) NULL COMMENT "��������",
����`dt` date NULL COMMENT "����",
����`period_type` varchar(65533) NULL DEFAULT "daily" COMMENT ""
����) ENGINE=OLAP
����DUPLICATE KEY(`index_id`, `user_id`, `biz_channel_name`, `pro_id`, `city_id`)
����PARTITION BY RANGE(`dt`)(
����PARTITION p20210731 VALUES [('2021-07-31'), ('2021-08-01')),
����PARTITION p20210801 VALUES [('2021-08-01'), ('2021-08-02')),
����PARTITION p20210802 VALUES [('2021-08-02'), ('2021-08-03')),
����PARTITION p20210803 VALUES [('2021-08-03'), ('2021-08-04')),
����PARTITION p20210804 VALUES [('2021-08-04'), ('2021-08-05')),
����PARTITION p20210805 VALUES [('2021-08-05'), ('2021-08-06')),
����PARTITION p20210806 VALUES [('2021-08-06'), ('2021-08-07')),
����PARTITION p20210807 VALUES [('2021-08-07'), ('2021-08-08')),
����PARTITION p20210808 VALUES [('2021-08-08'), ('2021-08-09')))
����DISTRIBUTED BY HASH(`index_id`, `user_id`) BUCKETS 10
����PROPERTIES (
����"replication_num" = "3",
����"dynamic_partition.enable" = "true",
����"dynamic_partition.time_unit" = "DAY",
����"dynamic_partition.time_zone" = "Asia/Shanghai",
����"dynamic_partition.start" = "-2147483648",
����"dynamic_partition.end" = "1",
����"dynamic_partition.prefix" = "p",
����"dynamic_partition.replication_num" = "-1",
����"dynamic_partition.buckets" = "3",
����"in_memory" = "false",
����"storage_format" = "DEFAULT"
����);
��������������ʹ����StarRocks����ϸģ���������������û���ѯ©����ϸ���ݵ�ʹ�ó���������ϸ���ϸ��ݲ�ͬ�Ķ�ά©��������ѯ������Ӧ���ﻯ��ͼ���������û�ѡ��ͬά�Ȳ鿴©��ģ��ÿһ�����û���ȷȥ��������ʹ�ó�����
����5������bitmap_union�ﻯ��ͼ������ѯ�ٶȣ�ʵ��count(distinct)��ȷȥ�أ�
���������û���Ҫ��©��ģ���ϲ鿴һЩ�����û�ת�������
������ѯһ��Ϊ��
����select city_id, count(distinct new_user_id) as countDistinctByID from fact_log_user_doris_table where `dt` >= '2021-08-01' AND `dt` <= '2021-08-07' AND `city_id` in (11, 12, 13) group by city_id
����������ָ��ݳ�����ȷ�û������ij��������ǿ�������ϸ��fact_log_user_doris_table�ϴ���һ���� bitmap_union ���ﻯ��ͼ�Ӷ��ﵽһ��Ԥ�Ⱦ�ȷȥ�ص�Ч������ѯʱStarRocks���Զ���ԭʼ��ѯ·�ɵ��ﻯ��ͼ���ϣ�������ѯ���ܡ�������case�����ĸ��ݳ��з��飬��user_id���о�ȷȥ�ص��ﻯ��ͼ���£�
����create materialized view city_user_count as select city_id,bitmap_union(to_bitmap(new_user_id)) from fact_log_user_doris_table group by city_id;
������StarRocks�У�count(distinct)�ۺϵĽ����bitmap_union_count�ۺϵĽ������ȫһ�µġ���bitmap_union_count����bitmap_union�Ľ���� count�����������ѯ���漰��count(distinct) ��ͨ��������bitmap_union�ۺϵ��ﻯ��ͼ���ɼӿ��ѯ����Ϊnew_user_id������һ��INT���ͣ������� StarRocks ����Ҫ�Ƚ��ֶ�ͨ������to_bitmapת��Ϊbitmap����Ȼ��ſ��Խ���bitmap_union�ۺϡ�
�����������ֹ���ȫ���ֵ�ķ�ʽ������ͨ��ÿ���賿��Spark����ͬ������ʵ��ȫ���ֵ�ĸ��£��Լ���ԭʼ���� Value �е��滻��ͬʱ��Spark�������û��ߺ�������������������������������к����ݵ�ȷ�ԣ�ȷ��������Ӫ���г�ͬѧ�ܿ���֮ǰ����Ӫ����û�ת���ʲ�����Ӱ�죬�Ա����Ǽ�ʱ������Ӫ���ԣ���֤�ճ���Ӫ�Ч����
����������������
����������Ʒ���з�ͬѧ�Ĺ�ͬŬ�������Ǵ���Ҫ��ѯ�ij���������ʱ���ȡ�����������ά�ȶԾ�ȷȥ�ع��ܽ����Ż����ڼ���������150������ID��ȷȥ�ز�ѯ�����ʱ3�����ڣ�������©������������Ч����
����δ���滮
����1.����StarRocks�ڲ��������Ŀ�����ͬ�εδ����ݵ���ƽ̨�����ݿ���ƽ̨���ϣ�ʵ��MySQL��ES��Hive�����ݱ�һ������StarRocks��
����2.StarRocks����һ�彨�裬����StarRocks�ṩ�˷ḻ������ģ�ͣ����ǿ��Ի��ڸ���ģ�ͺ���ϸģ���Լ��ﻯ��ͼ��������һ������ݼ�����洢ģ�ͣ�Ŀǰ���ڷ�����ؽΣ����ƺ���ƹ㵽���ĸ�����������ݲ�Ʒ�ϡ�
����3.����StarRocks On ElasticSearch��������ʵ���칹����Դ��ͳһOLAP��ѯ�����ܲ�ͬ������ҵ�����������ݼ�ֵ������
������������Ҳ�������עStarRocks�����ڲ����ϵ������������ڴ�StarRocks���ṩ���ḻ�Ĺ��ܣ������ŵ���̬��StarRocks����Ҳ����ΪOLAPƽ̨����Ҫ�����ʵ��OLAP���ͳһ�洢��ͳһ������ͳһ������
��������¼���߹���¼��������¼�����¼�ɷ����ʼ���news#citmt.cn����#����@����
������������ϵ�������������������ݿ�����������ϵ�����ұ�������������
IT��ҵ��&WWW.CITMT.CN © 2016-2018 ��ICP��18015839��-1![]() ���������� 42112402000149��
���������� 42112402000149��
רעIT��ҵ������IT��ҵ�� IT��ҵ��̬��ֵ����ƽ̨ ������
������ʾ:�������ݽ����Ķ�,������Ͷ�ʽ���,������Դ���
