2023/12/21 17:57 IT��ҵ��
����������ģ��(LLM)�Ѿ��ڶ������չʾ����Խ�����ܺ;��DZ����Ȼ����Ҫ���������ӳ���Щģ�͵�ǿ����������Ҫǿ�������������ʩ����оƬ�ǹؼ���
����ǧ����ʼ�����������Ӣ�ض�®️ ��ǿ®️ ����չ��������������!
����������һ�仰�����������ص㣬�Ǿ���——AIζ��Խ����Ũ��
������ѵ����������ģ��Ϊ����
������ ����Ĵ���ȣ�ѵ�������������29%���������������ߴ�42%;
������ ���������ȣ�AIѵ�����������������ߴ�14����

����ʲô����?
�����������ǽ�������200�ڲ�����ģ��“Ͷι”���������ǿ®️ ����չ����������ôʱ�ӽ��͵�������100����!
����Ҳ����˵��������CPU���ܴ�ģ�ͣ���ʵ�Ǹ����ˡ�
��������Ҳ����Ӣ�ض��ڴ˴η����е�һ�磬�����������Լ�“����”������Ϊ��ʮ�������ش�ܹ�ת��Ŀ��™️ Ultra��
�����˾����ǽ�AI��powerע�뵽���Ѽ�PC�У����ڼ��ٱ��ص�AI������
��������֮�⣬���嵽Ӣ�ض������ڸ��и�ҵ������AIʵսӦ�ã��������ݿ⡢��ѧ���㡢����ʽAI������ѧϰ���Ʒ���ȵȣ�Ҳ���ŵ������ǿ®️ ����չ�������ĵ������������õ���Ӣ�ض�®️ AMX��Ӣ�ض�®️ SGX/TDX���������ü������İ����£��õ��˸���Ľ�����Ч��
�����ܶ���֮���ݹ�Ӣ�ض��˴������ķ�����AI��ν�ᴩʼ�ա�
��������Ӣ�ض���������AI��Power��
���������������������˽�һ�µ������ǿ®️ ����չ��������¶�ĸ���ϸ�ڡ�
���������������Ż����棬Ӣ�ض������ֲ�����������������
������ CPU�����������ӵ�64�����������ܸ��ߣ�ÿ���ں˶��߱�AI���ٹ���
������ ����ȫ��I/O����(CXL��PCIe5)��UPI�ٶ�����
������ �ڴ������4800 MT/s�����5600 MT/s
������������������Ӣ�ض�ǰ������Ʒ�����Ƚϣ���ô���������Ľ���������ģ�
������ ����һ����Ʒ��ȣ���ͬ����ƹ�����ƽ����������21%;���������Ʒ�ȣ�ƽ����������87%��
������ ����һ����Ʒ��ȣ��ڴ���������ߴ�16%����������������������3��֮�ࡣ
�������ѿ������������ǿ®️ ����չ��������“ǰ����”��ȣ��ڹ������������ʵ�����˲�С��������
������Ӣ�ض��ɲ���������¶�������Ѿ����������ǿ®️ ����չ������������������ʵ��ʵ��ʹ��Ч��չʾ�˳�����
���������ڴ�ģ�͵��������棬�����Ʊ����ֳ�չʾ�˴��ص������ǿ®️ ����չ����������һ�����з����������ֵ�����——
����ȫ���Գ���20%����������“����”����!

����������ԣ�����������һ�����з������������µ�����������
������ ��������������123%;
������ AI������Ӿ���������������138%;
������ Llama 2��������������151%��
������Ҳ��һ��֤�����������ǿ®️ �ϸ��ģ�ͣ���Խ���ó����ˡ�
���������˴�ģ��֮�⣬���漰AI�ĸ���ϸ�������������������ڴ��������Ƶ�����ȵȣ�Ҳ��ͬ����ʵ������
������ݽ���������Բ����˵����Ӣ�ض�® ��ǿ® ����չ�������Ļ�ɽ����——
������ȫ�������ĵ��������Լ���ʵ����������������39%;Ӧ�������������43%��

�������������������Ļ����ϣ��ݻ�ɽ����¶��ͨ������еij�ϫ��Դ���������������˰���˵�����Դ�أ��ܹ��ý��ư��µijɱ��ṩ����ʹ�����飬���Ƴɱ�������!
������������ʹ�������ڵ������ǿ®️ ����չ�������еļ�����ʱ���ɽ�ÿ������ƽ������10��;���ܺĵ���105W��ͬʱ��Ҳ������Թ��������Ż��ĸ���ЧSKU��
��������˵��ʵ��ʵ�Ľ�����Ч�ˡ�
�������Ƽ���Ͱ�ȫ�Է��棬����ʵ�������ͬ�������Թ��ڵĴ�——�����ơ�
�����ڴ��ص����Ӣ�ض�® ��ǿ® ����չ�������������õ�Ӣ�ض�® AMX��Ӣ�ض�® TDX������������ƴ�����“����ʽAIģ�ͼ����ݱ���“�Ĵ���ʵ����ʹ��8��ECSʵ���ڰ�ȫ�Ժ�AI�����϶�����������������ұ���ʵ���۸䣬�ջݿͻ���
�������������������25%��QAT�ӽ�����������20%�����ݿ���������25%���Լ�����Ƶ��������15%��

����ֵ��һ����ǣ����õ�Ӣ�ض�®️ SGX/TDX������Ϊ��ҵ�ֱ��ṩ��ǿҲ�����õ�Ӧ�ø�������������� (VM) ����ĸ���ͱ����ԣ�Ϊ����Ӧ���ṩ��һ�������������ִ�л���Ǩ�Ƶ�·����
�����Լ������Ӣ�ض�® ��ǿ® ����չ��������������������������һ�����ݵģ������Դ����ٲ��Ժ���֤������
�����ܵ���˵���������ǿ® ����չ��������ν“��������”�����ַdz����ۣ�����������¶�����ģ�����Ӣ�ض���AI����һֱ���dz�������ص�̬�ȡ�
����������һ��AI���ʷ
������ʵ�ϣ���Ϊ������/������оƬ��Ӣ�ض�® ��ǿ® ����չ��������2017���һ����Ʒ��ʼ������Ӣ�ض�®️ AVX-512������ʸ������������AI���м����ϵij���;��2018���ڵڶ�����ǿ®️ ����չ�������е������ѧϰ���ټ���(DL Boost)��������ǿ��Ϊ“CPU��AI”�Ĵ�����;��֮����������������ǿ®️ ����չ���������ݽ��У���BF16�������ٵ�Ӣ�ض�®️ AMX����פ������˵Ӣ�ض�һֱ�ڳ������CPU��Դ�ĵ�·�����������ÿһ��������CPU����֧�ָ��и�ҵ�ƽ�AIʵս��
�����������ڴ�ͳ��ҵ��
��������ڶ�����ǿ®️ �ͷ����������죬������ҵ�������ʵʱ���ݴ�����ս������������ϵͳЧ�ʣ����“���ۿɼ�”�IJ�����չ��
���������ǿ® ����չ��������ʼ�ڴ�ģ�ͽ��չ���֡�
������AlphaFold2����ĵ������۵�Ԥ���ȳ�֮�У��������͵��Ĵ���ǿ® ����չ���������������������Ż��˵���ͨ��������ʵ�ֱ�GPU�����Լ۱ȵļ��ٷ�����ֱ������AI for Science���볡�ż���

���������о��дӵ��Ĵ���ʼ������CPU�У��������ѧϰӦ���Ƴ��Ĵ���AI��������——Ӣ�ض�® AMX�Ĺ��͡���Ϊ������صļ������������������ٻ���CPUƽ̨�����ѧϰ������ѵ��������AI�������ܣ���INT8��BF16�ȵ;����������Ͷ��������õ�֧�֡�
�������ͬʱ���ڴ�ģ��ʱ����OCR����Ӧ�ã�Ҳ�����Ĵ���ǿ® ����չ�������������µ�“���”��ȷ���������Ӧ�ӳٸ��͡�
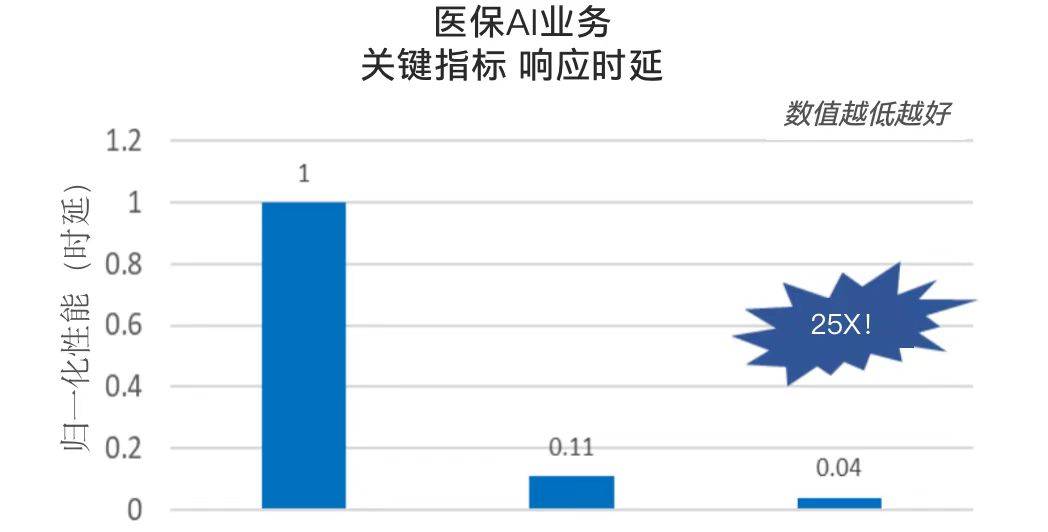
����ͬ�������ڲ���֮ǰ���������Ĵ���ǿ®️ ����չ��������NLP�ϵ��Ż���ר��ҽ����ҵ�Ĵ�����ģ��Ҳ�ɹ��Խϵͳɱ���ҽ�ƻ���������ء�
������AI����Խ��Խ������и�ҵ�Ĵ�����֮�£���ǿ® ����չ�����������ǿ���������������CPU�ⷨ��ȫ�ܹ�������Ϊ���ܹ��ò���AIӦ���ڲ����Ϊ�㷺����ȡ�������ס�Ӧ���ż�Ҳ���͵�CPUƽ̨�ϻ��ʵʵ���ڵ���ؿ�����
�����������ǿ® ����չ�������ķ���������������̸���һ����
������Ȼ——
������һ�ɼ��ı���ȷʵ����Ϊ��Ҷ�“��CPU����AI”��������������Լ�������Ҳ�м������ļ�ֵ�����ơ�
������˵���������Ǵ�ͳ��ҵ�ƽ����ܻ����죬����AI for Science������ʽAI�����˼��������չ������Ҫǿ���������������
������������ٵľ���ȴ�ǣ�ר�ŵļ���оƬ����Ӧ�ɹ��Ѳ�˵���ɱ�Ҳʮ�ָ߰�����˻�ԶԶ�����ռ���
��������һ��������Ȼ��Ŀ��Ͷ��CPU��
���������ʵ����Ϊ“���ֿɼ�”��Ӳ�������ֱ�Ӽ������ã������°빦��?
�����������CPU�ļ�ֵ�����ơ�
�������õ������Ż�������ʽAI��˵��������������������ռ���һ�������͵þ����ܵؿ��Ƴɱ���
�������ѵ����˵��AI��������������Դ����û����ô���ţ�����CPU��ȫ�ܹ�ʤ��——�����ӳٸ��ͣ���ЧҲ���ߡ�
������һЩ��ҵ��ҵ����������û����ô���أ�ѡ��CPU���ɸ����Լ۱ȡ�
�������⣬����CPUֱ�ӽ��в���������ҵ������ü���IT������ʩ�������칹ƽ̨�IJ������⡣
�������ϣ�����Ҳ���ܹ����⣺�ڴ�ͳ�ܹ�������AI���٣�����CPU�����ʱ������������
������Ӣ�ض����ģ����ǽ߾�ȫ�������ھ��ͷ����еļ�ֵ��
������Ԧ����AI���ߣ��Ҳ�ֹCPU
������������ٻص���������ǣ������Ӣ�ض�® ��ǿ® ����չ��������

����ʵ��˵�������ר�ŵ�GPU��AI����оƬ��ȣ�������ȷʵ�������ţ���������������(���伴�ã�������������̬Խ������)��
������ֵ������ע����ǣ���������ר�ü������ij��ϣ�CPU�����Ǵ�����Ԥ����������ģ�Ϳ������Ż����ٵ������ʹ�ã�Ҳ���Գ�ΪAI pipeline��һ���֡�
������������������Ԥ�����Σ����ѿ��ԳƵ��������ǵĴ��ڡ�
������������GB����TB�ƣ�������������ݼ���������ǿ® ����չ������������ķ�����������ͨ��֧�ָ����ڴ桢����I/O���������ƣ��ṩ��Ч�Ĵ����ͷ�������ʡAI��������һ�������ʱ�����ʱ�䡣
�����������ϣ�����Ҳ���ò���̾�����Ӣ�ض���̸AIʱ��������������ˡ�
�����ټ�������GPU��ר�ŵ�AI����оƬ��Ҳ�в��֣�“������”���ѡ��Ҳ�����ˣ��������ǵ�����Ҳ��ȫ���ˡ�
�����������ʣ���һ�У���ָ��Ӣ�ض�ȫ�����AI�ľ��ġ�
��������һϵ�о����Լ۱ȵIJ�Ʒ������������㲻ͬ��ҵ��AI�������
����AI ���ʱ����ʼ�ˣ�Ӣ�ض��Ļ���Ҳ����?

��
��������¼���߹���¼��������¼�����¼�ɷ����ʼ���news#citmt.cn����#����@����
������������ϵ�������������������ݿ�����������ϵ�����ұ�������������
IT��ҵ��&WWW.CITMT.CN © 2016-2018 ��ICP��18015839��-1![]() ���������� 42112402000149��
���������� 42112402000149��
רעIT��ҵ������IT��ҵ�� IT��ҵ��̬��ֵ����ƽ̨ ������
������ʾ:�������ݽ����Ķ�,������Ͷ�ʽ���,������Դ���
