2023/08/18 17:23 Donews
随着人工智能技术的发展,机器学习应用场景越来越广泛,从智能语音助手到自动驾驶,从智能推荐到图像识别,都需要大量的计算资源来支持。而GPU作为一种高效的计算资源,越来越受到关注,成为机器学习加速计算的重要工具。然而,跨硬件通用加速缺乏跨平台跨硬件的通用API,不同显卡实现高效算子十分困难和复杂。
作为头部科技企业,腾讯一直致力于推动人工智能技术的发展。因此,腾讯作为khronos会员积极参与新扩展标准制定,为机器学习加速计算提供更好的解决方案。在Vulkan 1.3.255版本中,腾讯联合ARM、NVIDIA、AMD、Google等诸多全世界科技企业一起带来新扩展VK_KHR_cooperative_matrix,这是腾讯首次参与khronos标准贡献。
Vulkan是通用的、跨平台的、新一代图形加速API,支持Windows、Linux、macOS、Android、iOS等多个操作系统。VK_KHR_cooperative_matrix扩展为Vulkan带来中尺度矩阵类型,用于加速矩阵计算,加速神经网络推理。这一新扩展使得非单一硬件绑定的通用AI计算加速成为可能,打破了行业垄断,带来了产业创新。Nvidia、ARM、AMD等显卡厂商将发布新驱动支持这个扩展标准,这将进一步推动机器学习加速计算的发展。
在VK_KHR_cooperative_matrix扩展标准的制定中,腾讯优图实验室参与制定。在标准修订过程中,腾讯优图实验室结合ncnn项目中的vulkan加速实践经验,主张新标准中的矩阵加载函数的stride参数允许为0,以便支持自动广播行为。这一参数能有效提升神经网络卷积和线性层计算中的bias数据处理效率。腾讯优图实验室专家,业界知名的开源神经网络推理库ncnn作者nihui表示:“khronos在线会议中,该提议获得各参与厂商技术人员认可和赞同,并成为硬性标准之一,要求在GPU驱动中实现该行为。”
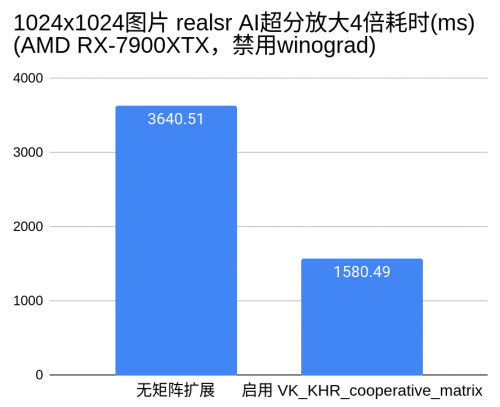
ncnn使用Vulkan API作为其跨平台GPU通用加速方案。ncnn通过使用VK_KHR_cooperative_matrix扩展,在AMD显卡上跑超分AI,速度提升约2.3倍。这也是VK_KHR_cooperative_matrix的首次应用,已发布在ncnn新版本中,带来更广泛的跨硬件厂商GPU加速。
腾讯参与制定VK_KHR_cooperative_matrix扩展标准,推动人工智能技术的发展,让机器学习的计算能力更加高效、普惠和可持续,为机器学习加速计算提供了更好的解决方案,实现跨平台跨硬件的通用API,使得机器学习加速计算更加高效、灵活。
一直以来,腾讯也在积极参与各类AI、大模型等方面的标准建设。2020年,腾讯被选举为全国信标委人工智能分委会委员兼副秘书长单位,这意味着国家在推进包括人工智能在内的“新基建”过程中,腾讯正作为核心成员,承担更多标准制定工作以及技术引领作用。前不久,腾讯云还联合中国信通院发起行业大模型生态计划,并牵头国内首个金融行业大模型标准制订,为金融行业智能化的高质量规范化发展提供重要支撑。
未来,腾讯将积极参与更多行业标准制定,助力更多行业提质增效,为人类社会带来更多的福祉。
榜单收录、高管收录、融资收录、活动收录可发送邮件至news#citmt.cn(把#换成@)。
关于我们┊联系我们┊友情链接┊内容开放┊内容联系┊独家报道┊法律声明
IT产业网&WWW.CITMT.CN © 2016-2018 鄂ICP备18015839号-1![]() 鄂公网安备 42112402000149号
鄂公网安备 42112402000149号
专注IT产业报道,IT产业网 IT产业生态价值发现平台 云自推
风险提示:文章内容仅供阅读,不构成投资建议,请谨慎对待。
