2023/10/23 15:19 IT��ҵ��
��������:ʯ���� ������ �������з�����ʦ
����ҵ����
�������������ɰ��ﶤ���������ѹ�ͬͶ�ʳ���,�����ͻ�����������Դ���ֻ�,������Ʒ������������ս�ԵĻ�������˾����˾��Ҫ�ṩ�������¹�����н��������籣��������ֵ�������ڵ�������ԴSaaS����,���ٶ�������Դ������,ʵ��������Դ�¹�����ʽ��Ŀǰ�ѷ�������������۷��������Ķ���ҵ�ͻ���
������������һ�ҵ��͵Ĵ�ҵ��˾,Ŀǰ����һ���������ҵ��г�������,��˾���ж��Ʒ����,ÿ����Ʒ�����ݾ��ж�����,ͬʱΪ������ڲ�CRM��������,���õذ���������,���������Ŷ���˵��һ����С����ս,���������Ŷ�Ҫ�������,,��ʱ��Ӧ����Ҫ�����ŶӼ�Ҫ�����ڲ�����������,Ҳ��Ҫ�ڼ���ijɱ���ʵ���Ż���
����ҵ��ʹ��
����MaxCompute��Ϊһ������Ĵ����ݲ�Ʒ,�䲻�����Ը��Լ۱ȷ���������������,ͬʱMaxCompute֧�ֿ����ӿں���̬,Ϊ���ݡ�Ӧ��Ǩ�ơ����ο����ṩ����ԡ�QuickBI����ֱ��MaxCompute�����������ݹ���˾�ڲ�������ͳ�ơ����ߡ���Ϊ��˾��ͨ��MaxCompute�ǰ������ѹ��,���Լ��������QuickBI ����ÿ�β�ͬ�IJ�ѯ����ķѼ�����Դ����MaxCompute�����������,�ڹ�ȥ��һ��ʱ��,MaxComputeÿ���µijɱ������ϴ�,����������ֵ,�Ҳ�����Ч����ʱ�ķ���һЩ�߳ɱ�sql�Ͷ�Ƶ���ʱ������ݼ���
��������ԭ�����
�������� MaxCompute �˵����ַ��ò�������Ϊ����������QuickBI�������ݼ����Զ���sql,��ҪΪ������㡣
����1����SQL��ѯ���ýϸ�
����MaxCompute����Ͳ���QuickBI��������ʱ��ά�������в�ѯ����,������Щʱ���ѯ��Ƚϴ�,��������������Ӷ��γ�һ�����ѯsql��
����2������������
��������MaxCompute�������ͱ������ݼ����ò�����,��Щ��ѯ��ֱ�Ӳ�ѯ��3�����������, ��ɼ���ɱ��������ӡ�
����3����������Ƶ�ʸ�,ɸѡ�ͬ
��������QuickBI���������ݼ��ɱ���ʵ�ܵ�,����ÿ����ʵĴ���ȷʵ�ܴ�,�����ظ�ִ�����MaxCompute������ҵ������,�Ӷ����¼���������ӡ�
����4�����ݱ�������ά������
�������ֱ������ݼ�Ϊ�˼������ݲ���,��Ҫ���Ӳ���ά�����������й���,����Щά�����ݼ���ʵ�ܴ�,���Ҳ���γ�һ�����ѯsql��
����5������ʱ��ϳ�
����MaxCompute���ּ���sql��QuickBI�������ݼ�����ʱ��ϳ�,Ӱ������ҵ������ʱ��ͱ������ݲ�����
��������Information Schema������Ŀ��ҵ
����MaxComputeԪ���ݷ���Information Schema�ṩ����ĿԪ���ݼ�ʹ����ʷ���ݵ���Ϣ����ANSI SQL-92��Information Schema������,����������MaxCompute�������е��ֶμ���ͼ��
�����⻧����Information Schema��ԭ��Ŀ����Information Schema��������,����ÿ���������˺��´�����ΪSYSTEM_CATALOG����Ŀ,������Information Schema,ͨ�����ʸ�����Schema�ṩ��ֻ����ͼ,��ѯ��ǰ�û�������Ŀ��Ԫ������Ϣ�Լ�ʹ����ʷ��Ϣ��Ԫ������ͼ�б�����

�����������ϲ�����ͼԪ������Ϣ,���Ǹ����ĵ���Information_Schema.TASKS_HISTORY����ÿ����������ʱ�䡢�ɱ��ʹ�����
��������SQL�ű�
������������ʹ�õ����⻧����� Information Schema,�������Ŀ����� Information Schema,�⻧�����ֻ��Ҫ����һ������ڵ�Ϳ��Լ������� project ������,����Ŀ����� Information Schema ÿ�� project ����Ҫһ������ڵ�,������Ƽ��⻧����� Information Schema��
set odps.namespace.schema=true;set odps.sql.decimal.odps2=true;create table if not exists ads_project_cost_pay_di ( env_type string comment '��������' ,cost_type string comment '��������' ,inst_id string comment 'Ψһid,��ҵid' ,owner_name string comment '��ҵ������' ,task_type string comment '��ҵ���� SQL:SQL��ҵ CUPID:Spark��Mars��ҵ SQLCost:SQLԤ����ҵ SQLRT:��ѯ����SQL��ҵ LOT:MapReduce��ҵ PS:PAI��Parameter Server AlgoTask:����ѧϰ��ҵ' ,input_records string comment '��ҵ�����records��Ŀ' ,output_records string comment '��ҵ�����records��Ŀ' ,input_bytes string comment 'ʵ��ɨ���������,��Logview��ͬ��' ,output_bytes string comment '����ֽ�����' ,status string comment '���ݲɼ�˲�������״̬(��ʵʱ״̬)����������״̬:Terminated:��ҵ��ִ�н�����Failed:��ҵʧ�ܡ� Cancelled:��ҵ��ȡ����' ,cost_pay DECIMAL(18,5) comment '���� ��λԪ' ,complexity string comment '�����Ӷ�' ,settings string comment '�ϲ���Ȼ��û��������Ϣ,��JSON��ʽ�洢�������ֶ�:USERAGENT��BIZID��SKYNET_ID��SKYNET_NODENAME��' ,sql_script string comment 'sql ����' ,start_time string comment '��ʼʱ��' ,end_time string comment '����ʱ��' ,data_collection string comment 'quickbi���ݼ�')comment 'odps ���� ��ϸ'partitioned by (ds string comment '����') ;insert overwrite table ads_project_cost_pay_di partition(ds=${bizdate})select case when task_catalog = 'renlijia_ng' then '����' when task_catalog = 'renlijia_ng_dev' then '����' else task_catalog end as env_type ,if(regexp_count(settings,'quickbi')>0,'quickbi',task_catalog)cost_type ,inst_id ,owner_name ,task_type ,input_records ,output_records ,input_bytes ,output_bytes ,status ,nvl(case when task_type = 'SQL' then cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) ) when task_type = 'SQLRT' then cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) ) when task_type = 'CUPID' and status='Terminated'then cast(cost_cpu/100/3600 * 0.66 as DECIMAL(18,5) ) else 0 end,0) cost_pay ,complexity ,settings ,operation_text sql_script ,start_time ,end_time ,regexp_extract(operation_text,'(?<=quickbi=).*?(?==quickbi)',0)data_collectionfrom SYSTEM_CATALOG.INFORMATION_SCHEMA.TASKS_HISTORY where ds=${bizdate};ע:sql�ɱ����㹫ʽ(�ٷ�ʾ��):ע:sql�ɱ����㹫ʽ(�ٷ�ʾ��):
case when task_type = 'SQL' then cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) ) when task_type = 'SQLRT' then cast(input_bytes/1024/1024/1024 * complexity * 0.3 as DECIMAL(18,5) ) when task_type = 'CUPID' and status='Terminated'then cast(cost_cpu/100/3600 * 0.66 as DECIMAL(18,5) ) else 0 end; ����ǰ��MaxCompute����ɱ��Ա�
��������������ϸ����
��Ϊ��˾�ǰ������ѵ�MaxCompute,����������Ҫ���ĵ��dzɱ�����ͱ����ķ���������Դ�������Ҫ�ӻ��������ݼ����û���ά�Ƚ��з�����
QuickBI���ݼ�(��ads_project_cost_pay_di��)
����QuickBI����Demo
����QuickBI���ݼ��ֶ��Ǵ�sql-script������ƥ�����,��QuickBI���ݼ���Ҫ��������һ���ֶ�������ȡ���ݼ�����
��1���ֶ���QuickBI���ݼ����������ֶ�:
‘quickbi=xxx���ݼ�=quickbi’ as ���ݼ��Զ����ֶ�
2������MaxCompute����regexp_extract�������·�ʽ����ƥ��:
regexp_extract(operation_text,'(?<=quickbi=).*?(?==quickbi)',0)
�����Ľ���:
1���滻�������������ݱ������ݼ���
2��ά���������ϲ�ӹ�,�²����������,�������ֻ��һ�ű���
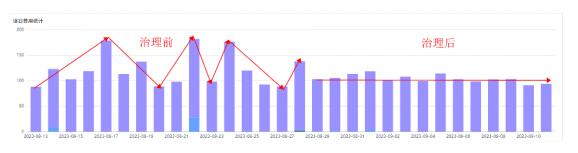
��3����Ƶ�������ݼ��Ż��洢��С��QuickBI �����DZ���������
4�����ٱ�������ʱ�䡣
����:����MaxCompute �⻧����Information Schema,��ȡÿ����ʷ��ҵ��Ϣ,��˾�ɹ���ÿ��MaxCompute�ɱ����͵������������䡣
��������¼���߹���¼��������¼�����¼�ɷ����ʼ���news#citmt.cn����#����@����
������������ϵ�������������������ݿ�����������ϵ�����ұ�������������
IT��ҵ��&WWW.CITMT.CN © 2016-2018 ��ICP��18015839��-1![]() ���������� 42112402000149��
���������� 42112402000149��
רעIT��ҵ������IT��ҵ�� IT��ҵ��̬��ֵ����ƽ̨ ������
������ʾ:�������ݽ����Ķ�,������Ͷ�ʽ���,������Դ���